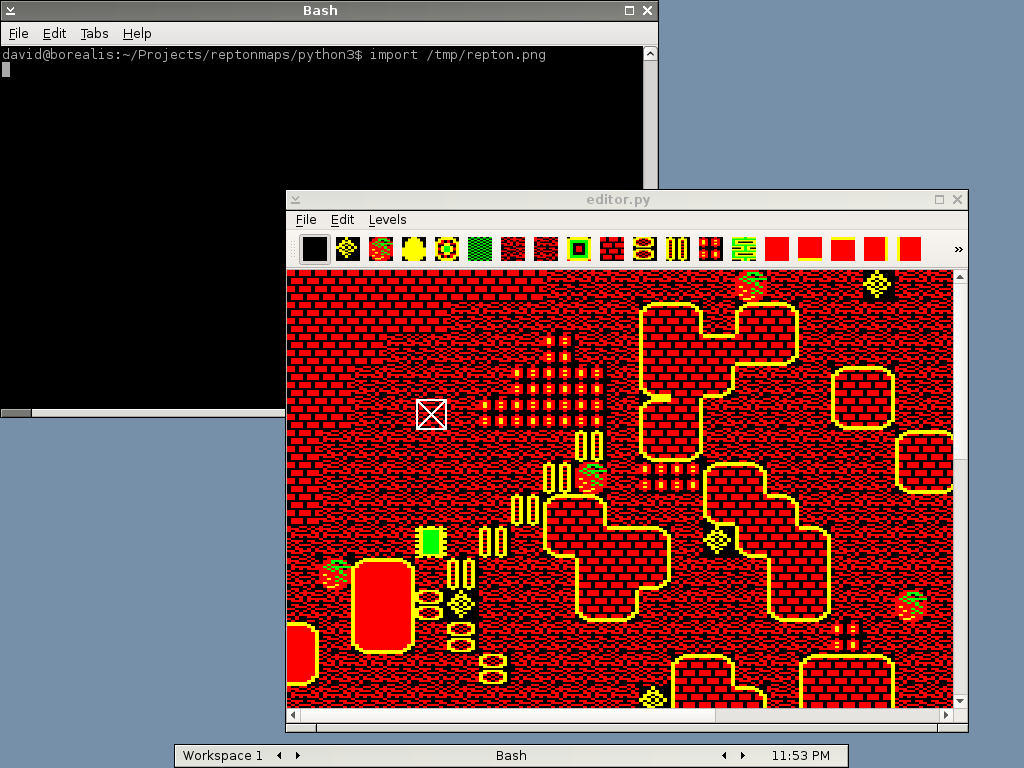
The end result.
Last year I looked at Debian GNU/Hurd, using the network installer to set up a working environment in kvm. Since them I haven't really looked at it very much, so when I saw the announcement of the latest release I decided to check it out and see what has changed over the last few months. I also thought it might be interesting to try and run some of my own software on the system to see if there are any compatibility issues I need to be aware of. This resulted in a detour to port some code to Python 3 and a few surprises when code written on a 64-bit system found itself running on a 32-bit system.
As before, I created a blank disk image, downloaded the network installer and booted it using kvm:
qemu-img create hurd-install-2017.qemu 5G wget http://ftp.ports.debian.org/debian-ports-cd/hurd-i386/debian-hurd-2017/debian-hurd-2017-i386-NETINST-1.iso sha512sum debian-hurd-2017-i386-NETINST-1.iso # Check the hash of this against those listed on this page. kvm -m 1024M -drive file=hurd-install-2017.qemu,cache=writeback -cdrom debian-hurd-2017-i386-NETINST-1.iso -boot d -net user -net nic
The default pseudo-graphical installation method seems to work well, though the graphical one also worked nicely. The text-based method didn't seem to work at all. After doing all the usual things a Debian installation process requires, such as defining the keyboard layout and partitioning disks, it's possible to boot the hard disk image and get going with GNU/Hurd again. I use the -redir option to allow me to log into a running environment with ssh via a non-standard port on the host machine:
kvm -m 1024M -drive file=hurd-install-2017.qemu,cache=writeback -cdrom debian-hurd-2017-i386-NETINST-1.iso -boot c -net user -net nic -redir tcp:2222::22
The Debian GNU/Hurd Configuration page covered all the compatibility issues I encountered, though some issues mentioned there did not cause problems for me. For example, I didn't need to explicitly enable the swap partition. On the other hand, I needed to reconfigure Xorg, as suggested, to allow any user to start an X session; not the "Console Users Only" option, but the "Anybody" option.
I tried running a few desktop environments to see which of those that run I would like to use, and which of those run acceptably in kvm without any graphics acceleration. Although MATE, LXDE and XFCE4 all run, I found that I preferred LXQt. However, none of these were as responsive as Blackbox which, for the moment, is as much as I need in a window manager.
The end result.
With a graphical environment in place, I wanted to try some software I'd written to see if there were any compatibility issues with running it on GNU/Hurd. I decided to try one of my tools for editing retro game maps. However, it turned out that this PyQt 4 application wouldn't run correctly, crashing with a bus error. This seems to be a compatibility problem with Qt 4 because simple tests with widgets would fail with this library while similar tests with Qt 5's widgets worked fine. At this point it seemed like a good idea to port the tool to PyQt 5.
Since PyQt 5 is compatible with versions of Python from 2.6 up to the latest 3.x releases, I could have just tweaked the tool to use PyQt 5 and left it at that. However, I get the impression that many of the developers working with PyQt 5 are using Python 3, so I also thought it would be a good excuse to try and port the tool to Python 3 at the same time.
One of the first things that many people think about when considering porting from Python 2 to Python 3, apart from the removal of the print statement, is the change to the way Unicode strings are handled. In this application we hardly care about Unicode at all because, in the back end modules at least, all our strings contain ASCII characters. However, these strings are really 8-bit strings containing binary data rather than printable text, so we might welcome the opportunity to stop misusing strings for this purpose and embrace Python 3's byte strings (bytes objects). This is where the fun started.
First of all, we have to think about all the places where we open files, ensuring that those files are opened in binary mode, using the "rb" mode string. I've been quite careful over the years to do this for binary files, even though you could get away with using "r" on its own on many platforms. Still, it's good to be explicit and Python 3 now rewards us by returning byte strings. So we now pass these around in our application and process them a bit like the old-style strings. We should still be able to use ord to translate single byte characters to integer values; chr is no longer used for the reverse translation. The problems start when we start slicing up the data.
In Python 2, we can use the subscript or slicing notation to access parts of strings that we want to convert to integer values, perhaps using the struct module to ensure that we are decoding and encoding data consistently. When we access a string in this way, we get a string of zero or more 8-bit characters:
# Python 2: >>> a = "\x10ABC\0" >>> print repr(a[0]), repr(a[1:5]), repr(a[5:]) '\x10' 'ABC\x00' ''
In Python 3, using an equivalent byte string, we find that we get something different for the case where we access a single 8-bit character:
# Python 3: >>> a = b"\x10ABC\0" >>> print(repr(a[0]), repr(a[1:5]), repr(a[5:])) 16 b'ABC\x00' b''
In some ways it's more convenient to get an integer instead of a single byte string. It means we can remove lots of ord calls. The problem is that it introduces inconsistency in the way we process the data: we can no longer treat single byte accesses in the same way as slices or join a series of single bytes together using the + operator. The work around for this is to use slices for single byte accesses, too, but it seems slightly cumbersome:
# Python 3: >>> print(repr(a[0:1]), repr(a[1:5]), repr(a[5:])) b'\x10' b'ABC\x00' b''
This little trap means that we need to be careful in other situations. For example, where we might have iterated over a string to extract the values of each byte, we now need to think of an alternative way to do this:
# Python 2: >>> a = b"\x10ABC\0" >>> map(ord, a) [16, 65, 66, 67, 0]
# Python 3: >>> a = b"\x10ABC\0" >>> list(map(ord, a)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: ord() expected string of length 1, but int found
We could use the struct module's unpack function or pass a lambda that returns the value passed to it. Both of these seem a bit unwieldy for the case where we just want to access single bytes sequentially. There's probably an easy way to do this; it's just that I haven't learned the Python 3 idioms for this yet.
We also run into an interesting problem when we want to convert integers back into a byte string. For a list of integers, we use the bytes class as you might expect:
>>> a = [16, 65, 66, 67, 0] >>> bytes(a) b'\x10ABC\x00'
However, for a single integer, what do we do? Let's try passing the single value:
>>> a = 3 >>> bytes(a) b'\x00\x00\x00'
That's not what we wanted. We can't use the chr function instead because that's now used for creating Unicode strings. The answer is to wrap the value in a list:
>>> a = 3 >>> bytes([a]) b'\x03'
The conclusion here seems to be to keep all the values extracted from byte strings in lists and only use slices on them so that we can reconstruct byte strings more easily later. Most of the other problems I encountered were due to the lazy evaluation of built-in functions like map and range. Where appropriate, these had to be wrapped in calls to list.
Converting the GUI code to PyQt 5 was a minor task after the porting to Python 3 since the classes in the QtWidgets module behave more or less the same as before. For example, QFileDialog.getOpenFileName returns a tuple instead of a single file name, but this was quickly fixed, and I could discard a few obsolete calls to Python 2's unicode class.
Python 3's handling of byte strings is a mixed bag. On one hand I can see the benefits of exposing single bytes as integers, and understand that there is a certain logical consistency in expecting developers to use slices everywhere when handling byte strings. On the other hand it seems like a solution based on an idea of theoretical purity more than practicality, and it seems inconsistent with the approach of returning different item types for single and multiple values when accessing what is effectively still a string of characters.
With the Python 3 porting project out of the way, I turned my attention to a current Python 2 project. I wanted to see if my DUCK tools would run without problems. Initially, everything looked fine, as you might expect from taking something developed on one flavour of Debian and running it on another. However, testing the packages produced by the compiler led to unexpected crashes. To cut a long story short, the problem was due to an inconsistency in the Python type system on architectures of different sizes.
To illustrate the problem, let's assign an integer value to a variable on our 32-bit and 64-bit Python installations. Here's the 64-bit version:
# 64-bit >>> 0x7fffffff 2147483647 >>> 0xffffffff 4294967295
That looks fine. Just what we would expect. Let's see the 32-bit version:
# 32-bit >>> 0x7fffffff 2147483647 >>> 0xffffffff 4294967295L
So the second value is a long value in this case. That's useful to know, but it means we cannot rely on Python's type system to give us a single type for values up to the precision of Dalvik's long type. Another related problem is that the struct module defines different sizes for the long type depending on whether the platform is 32-bit or 64-bit.
These issues can be worked around. They help remind us that we need to test our software on different configurations. Incidentally, it seems that the int type is finally unified in Python 3, though the sizes of long integers are still dependent on the platform's underlying architecture.
I'll continue to play with GNU/Hurd for a while. The system seems pretty stable so far, with the only instabilities I've encountered coming from running different graphical environments under Xorg. I'll try to start looking at Hurd-specific features now that I have something I can conveniently dip into from time to time.
Categories: Free Software, Android, Python
Copyright © 2017 David Boddie
Published: 2017-06-30 17:09:35 UTC
Last updated: 2017-06-30 17:11:33 UTC
 This document is licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International license.
This document is licensed under the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International license.